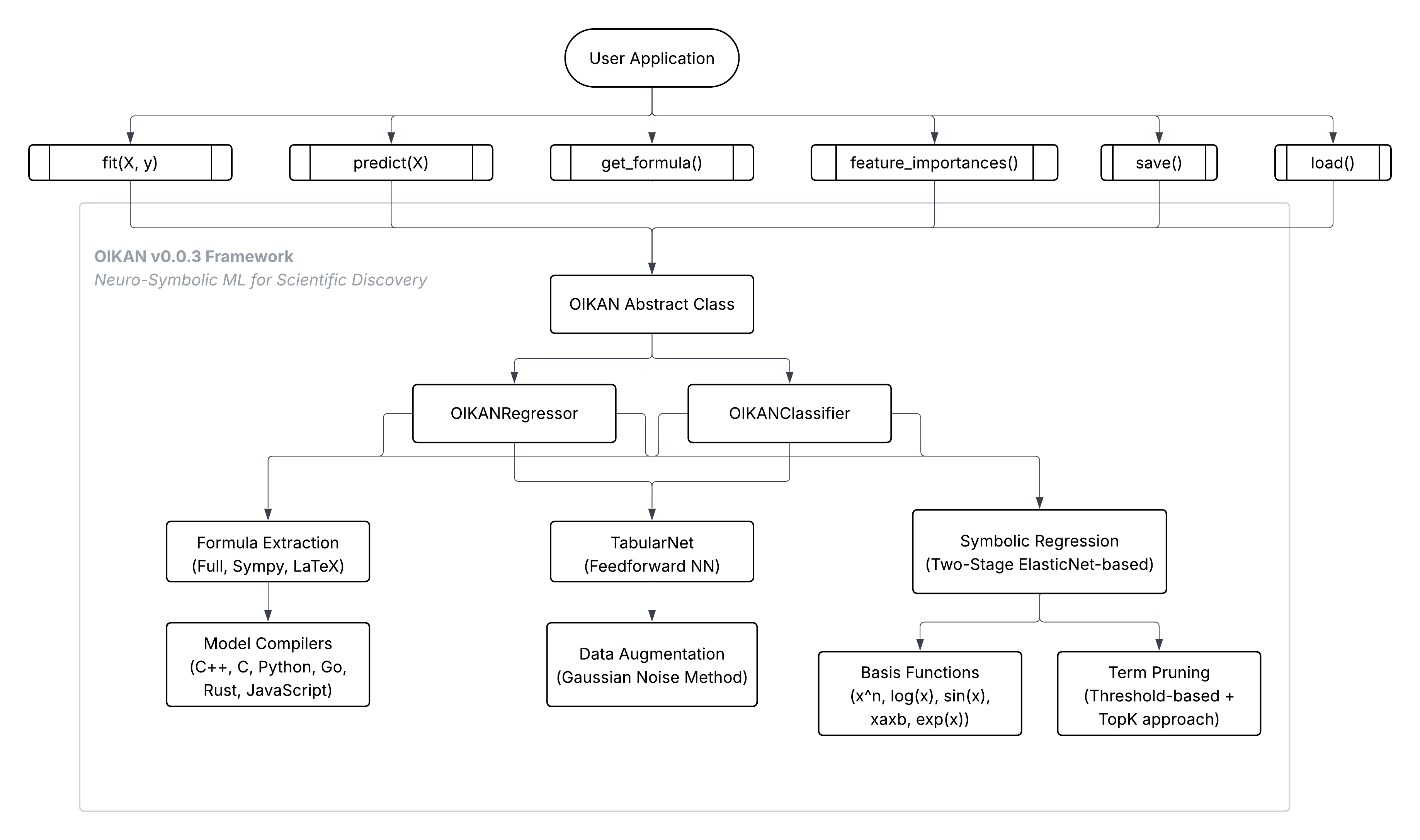
Regression Example
from oikan import OIKANRegressor
from sklearn.metrics import r2_score
# Initialize model
model = OIKANRegressor(
hidden_sizes=[32, 32], # Hidden layer sizes
activation='relu', # Activation function (other options: 'tanh', 'leaky_relu', 'elu', 'swish', 'gelu')
augmentation_factor=5, # Augmentation factor for data generation
alpha=1.0, # ElasticNet regularization strength (Symbolic regression)
l1_ratio=0.5, # ElasticNet mixing parameter (0 <= l1_ratio <= 1). 0 is equivalent to Ridge regression, 1 is equivalent to Lasso (Symbolic regression)
sigma=5, # Standard deviation of Gaussian noise for data augmentation
top_k=5, # Number of top features to select (Symbolic regression)
epochs=100, # Number of training epochs
lr=0.001, # Learning rate
batch_size=32, # Batch size for training
verbose=True, # Verbose output during training
evaluate_nn=True, # Validate neural network performance before full process
random_state=42 # Random seed for reproducibility
)
# Fit the model
model.fit(X_train, y_train)
# Make predictions
y_pred = model.predict(X_test)
# Evaluate performance
r2_value = r2_score(y_test, y_pred)
print("R2 Score:", r2_value)
# Get symbolic formula
formula = model.get_formula() # default: type='original' -> returns all formula without pruning | other options: 'sympy' -> simplified formula using sympy; 'latex' -> LaTeX format
print("Symbolic Formula:", formula)
# Get feature importances
importances = model.feature_importances()
print("Feature Importances:", importances)
# Save the model (optional)
model.save("outputs/model.json")
# Load the model (optional)
loaded_model = OIKANRegressor()
loaded_model.load("outputs/model.json")
Classification Example
from oikan import OIKANClassifier
from sklearn.metrics import accuracy_score
# Initialize model
model = OIKANClassifier(
hidden_sizes=[32, 32], # Hidden layer sizes
activation='relu', # Activation function (other options: 'tanh', 'leaky_relu', 'elu', 'swish', 'gelu')
augmentation_factor=10, # Augmentation factor for data generation (default: 1)
alpha=1.0, # ElasticNet regularization strength (Symbolic regression)
l1_ratio=0.5, # ElasticNet mixing parameter (0 <= l1_ratio <= 1). 0 is equivalent to Ridge regression, 1 is equivalent to Lasso (Symbolic regression)
sigma=5, # Standard deviation of Gaussian noise for data augmentation
top_k=5, # Number of top features to select (Symbolic regression)
epochs=100, # # Number of training epochs
lr=0.001, # Learning rate
batch_size=32, # Batch size for training
verbose=True, # Verbose output during training
evaluate_nn=True, # Validate neural network performance before full process
random_state=42 # Random seed for reproducibility (default: 42)
)
# Fit the model
model.fit(X_train, y_train)
# Make predictions
y_pred = model.predict(X_test)
# Evaluate performance
accuracy = accuracy_score(X_test, y_test)
print("Accuracy:", accuracy)
# Get symbolic formulas for each class
formulas = model.get_formula() # default: type='original' -> returns all formula without pruning | other options: 'sympy' -> simplified formula using sympy; 'latex' -> LaTeX format
for i, formula in enumerate(formulas):
print(f"Class {i} Formula:", formula)
# Get feature importances
importances = model.feature_importances()
print("Feature Importances:", importances)
# Save the model (optional)
model.save("outputs/model.json")
# Load the model (optional)
loaded_model = OIKANClassifier()
loaded_model.load("outputs/model.json")

-architecture-oop.png)